Developing an SBOM Workflow – Part 2: SBOM Consumption


Cover photo by Look Up Look Down Photography on Unsplash.
This is part two of the SBOM story which covers the consuming side. If you missed part one, you can find it here.
One would assume that with a standardized format the combinations of generator and consumer are interchangeable, but as noted previously, the SBOMs still vary in content and attributes.
Possible SBOM Consumers and Interoperability Troubles
Generating SBOMs is a nice first step of the workflow, but at some point you probably want to actually use them for something, and most people would prefer to use something more advanced than grep or a text editor. There is a good amount of possible tools to work with SBOMs, both the SPDX and the CycloneDX website contain a list. Most of the analysis tools provide license compliance, so there are not that many to work with them for vulnerability management, which is what we want to focus on for the secureCodeBox.
SBOM Consumers
There are still multiple options for consuming SBOMs when focusing on vulnerabilities. To integrate one of them with a hook for an SBOM workflow, a continuously running tool as a service is needed. This list nevertheless contains some tools, that are only usable for one-off analyses. These were used for general SBOM quality comparisons.
Trivy
Since Trivy is primarily a security scanner, it can also scan SBOMs for security vulnerabilities. Of course generating SBOMs with Trivy just to scan them with Trivy later is not the most interesting use case, especially since the secureCodeBox already supports Trivy scans. It does still serve as an interesting baseline, to compare Trivy SBOM scan results to direct Trivy scans.
When directly scanning the Juice Shop image, Trivy detects 23 issues in debian packages and 67 in node packages, some as "fixed" and some as "affected". Scanning the Juice Shop CycloneDX SBOM returns the same 23 debian issues, but only 51 node vulnerabilities. Comparing the lists shows that there are fewer reported vulnerabilities for the semver package. Turns out, that the same version of semver is included multiple times throughout the dependency tree, which gets deduplicated in the produced SBOM, but counted as individual vulnerabilities for the direct scan. Other than that the same vulnerabilities are reported. The SPDX SBOM contains all the semver usages and reports 67 node vulnerabilities again.
For the Syft SBOMs, Trivy reports only 8 debian vulnerabilities, all for openssl.
The ones for libc6 and libssl1.1 are not picked up.
For node 51 vulnerabilities are reported, which is interesting, because Syft does not deduplicate components in its SBOMs, so the same semver versions are listed multiple times.
Trivy also warns about inaccuracies in scans of third party SBOMs, which is unfortunate, after all the point of standards is interoperability.
Grype
Compared to Trivy, Syft is only a tool to generate SBOMs, not a security scanner to gain insight from SBOMs or other sources. Anchore offers a companion application to Syft, called Grype, which can then be used to scan SBOMs for vulnerabilities. Grype can also directly scan container images.
Scanning the same Juice Shop image with Grype directly reveals 87 security vulnerabilities. The same is true for scanning Syft's json or CycloneDX output. The SPDX output produces 71 vulnerabilities, the missing ones are again the deduplicated semver issue GHSA-c2qf-rxjj-qqgw. Scanning Trivy SBOMs with Grype reveals fewer issues, 56 for both the SPDX and the CycloneDX SBOM. Other than the missing duplicated semver issue, some glibc CVEs are missing and some OpenSSL vulnerabilities are only found for OpenSSL instead of for both OpenSSL and libssl.
If an SBOM does not contain CPEs, Grype offers to add them to improve vulnerability discovery. For the Trivy SBOMs this did not increase the amount of vulnerabilities recognized. In these tests, Grype vTODO was used.
Dependency-Track
The problem with both those tools is, that they are one-off invocations, consuming a single SBOM. A continuous SBOM workflow needs a continuosly running service to accept the SBOMs, which then get analyzed regularly and can be checked for components or vulnerabilities. OWASP Dependency-Track is a self hosted service that offers exactly that. SBOMs can be uploaded through the GUI or by using the API, but only in CycloneDX format, Dependency-Track does not support SPDX SBOMs. Support is planned again in the future, but depends on changes to the SPDX schema. After the import, Dependency-Track analyzes them and generates lists of components and vulnerabilities. Which vulnerabilities are recognized depends on the enabled analyzers and vulnerability sources. By default the Docker deployment I used enabled the Internal Analyzer and the Sonatype OSS Index as analyzers (even though the FAQ says OSS Index is disabled by default) and the National Vulnerability Database (NVD) as data source. The best practices recommend to additionally enable the GitHub Advisory Database as data source, which I did for later tests.
For the Juice Shop SBOM, without using the GitHub Advisory Database, Dependency Track finds 35 vulnerabilities in the Trivy SBOM and 88 in the one generated by Syft. This is a pretty big difference, which has multiple reasons. First of all, neither Syft nor Dependency-Track deduplicate packages, so each occurence of semver gets a new vulnerability entry for CVE-2022-25883. Then again, only Syft's SBOMs contain CPEs, which are needed to find and match vulnerabilities in the NVD.
After enabling the GitHub Advisory Database, Dependency-Track reports 87 vulnerabilities for the Trivy SBOM, and 156 for Syft's. It is not trivial to compare by which vulnerabilities this exactly differs, because they often have mutliple identifiers, which can lead to the same vulnerability getting reported multiple times. The counts of the severity categories also changed, but instead of strictly increasing there were more vulnerabilities of lower severity.
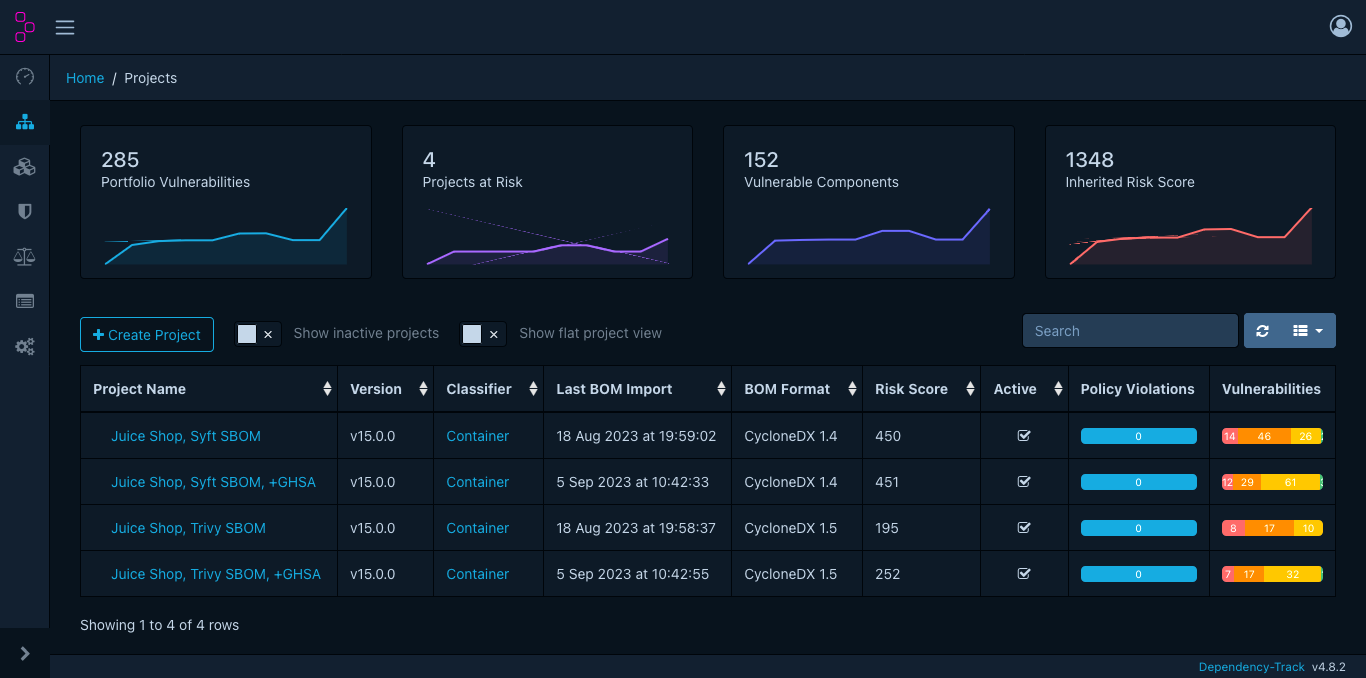
This is what the Dependency-Track dashboard looks like for those four projects, representing different analyses of the Juice Shop image. Dependency-Track 4.8.2 was used for the tests covered in this blogpost.
Others
As an OWASP project, Dependency-Track is a good first choice for an SBOM consumer and shows some of the problems which occur when building a complete SBOM workflow. There are other tools with similar functionality as well, but at this point selecting the best tool is not necessary. This is a collection of other possible tools that I did not test but which looked possibly fitting at a first glance, listed here as a reference.
The open source community DevOps Kung Fu Mafia develops a tool called bomber. Judging by the description it is very similar to Trivy or Grype, but instead of shipping or building their own combined vulnerability database, bomber directly checks vulnerabilities against either OSV, OSS Index or Snyk.
The FOSSLight Hub lists SBOM support (SPDX only) and vulnerability management as capabilities. Main usage and features seem to aim at license compliance though.
The Eclipse Foundation provides the software catalogue application SW360. It lists vulnerability management as one of its features and supports both SPDX and CycloneDX imports. There is currently a discussion going on about using it as an SBOM management tool.
The KubeClarity tool by OpenClarity provides Kubernetes, container and filesystem scanning and vulnerability detection. It uses a pluggable architecture to support multiple scanners and analyzers in a two step process with SBOMs as an intermediate product. Currently used scanners are Trivy, Syft and Cyclonedx-gomod. The analyzers are Trivy, Grype and Dependency-Track.
The Naming Problem
As mentioned multiple times, one of the differences between Trivy's and Syft's SBOMs are the Common Package Enumerations (CPEs) that only Syft includes. Among package urls (purls), they are a way of uniquely identifying software applications or packages, which is needed to match packages against vulnerabilities listed in a database. While many databases already include purls as references, the National Vulnerability Database (NVD) does not. This prevents the vulnerabilities, that are not duplicated to other databases (like Debian's) to get reported.
So if including CPEs improves vulnerability matching, why does Trivy not include them?
Because CPEs are difficult and inconvenient to work with.
Accurately but automatically assigning the correct CPE is not trivial, because the format includes a vendor field, which does not always match the most trivial guess.
This fits closed source software distributed by companies, but not the modern OSS environment of small packages by individual contributors.
There is an official CPE dictionary, which should be used to match components to CPEs, but even with that matching the correct software is not straightforward.
For redis for example, it contains among others Anynines redis (cpe:2.3:a:anynines:redis:2.1.2:*:*:*:*:pivotal_cloud_foundry:*:*), a product using redis, hiredis (cpe:2.3:a:redislabs:hiredis:0.14.0:*:*:*:*:*:*:*), a C client, and the in-memory data store most people would think of (used to be cpe:2.3:a:pivotal_software:redis:4.0.10:*:*:*:*:*:*:* but is now cpe:2.3:a:redislabs:redis:4.0.10:*:*:*:*:*:*:*).
Since CPEs are centrally managed, they are often only assigned when a vulnerability is reported, so proactively monitoring for vulnerabilities turns into a guessing game.
This describes Syft's strategy of assigning CPEs pretty well, try to generate CPEs on a best effort basis, which of course fails sometimes.
For Trivy there is an open issue to include CPEs, but it does not specifically mention SBOMs.
Because of these problems, CPEs were already deprecated by the NVD, with the intention of replacing them by Software Identification Tags (SWID) instead. Since the migration is currently not moving along, CycloneDX undeprecated CPEs again.
Package urls are a more recent naming scheme, which make automatic assignment a lot easier. Most other databases either directly support them already (like OSS Index or Google's OSV), or contain the information needed to work with them (like GitHub advisories, but including them is debated). The most important one that does not is the NVD, which is why there are multiple requests and proposals for purls to get added.
This problem, that there is no unique identifier for software products that works across ecosystems, is known as the naming problem among people working with SBOMs. There are several proposals for fixing the status quo, which all boil down to "the NVD needs to use purls" for at least part of their solution. The most important proposal is A Proposal to Operationalize Component Identification for Vulnerability Management, released September last year by a group calling themselves the SBOM Forum. In their statement, they also detail the problems of CPEs and propose using purls for identifying software, but other identifiers for hardware. Work is ongoing to improve the NVD but it is a slow process. Tom Alrich, the founder of the SBOM Forum, regularly informs about updates on his blog.
Other Problems with SBOMs
Apart from the naming problem, SBOMs are still not the perfect solution for software composition analysis. While SBOMs contain information about the software and version used, linux distributions often apply their own patches to the packages they distribute. These patches regularly include backported fixes for security vulnerabilities as part of a distributions long term support commitments. While getting this support is nice, it might lead to false positive vulnerability reports, because either the SBOM does not contain information about the specific distribution version of a package, or the vulnerability database it is matched against only contains information about fixes in the upstream version.
As an example, according to the NVD, CVE-2022-4450 affects openssl starting with 1.1.1 and is fixed in 1.1.1t.
The Debian advisory though reports, that a fix has been released for 1.1.1n-0+deb11u4, which is the version used in the Juice Shop image.
Dependency-Track still reports the vulnerability though.
This means, that for accurate reports, the security advisories of the individual distributions would need to be considered as well, which further complicates the vulnerability mapping.
Dependency-Track has an open issue about this, so this problem is known as well, but the solution is not straight forward.
Another devil hides in the details: just because a dependency is included, this does not mean, that a vulnerability is actually exploitable through the application using it. Depending on how deep in a dependency chain some library is included, it could range from trivial to impossible, to trigger the flaw at all. The application or top-level library using the vulnerable dependency might not even use the affected feature. SBOMs of course cannot judge that, they only inform about a component being present, which is the only information that consumption systems can rely on.
A possible solution for this problem is a Vulnerability Exploitability eXchange (VEX), basically a standardized security advisory. CycloneDX supports including vulnerability information, which can be used to build VEX. For applications, this can only be sensibly done by the vendor though, otherwise every consumer would need to individually analyze an application. For this reason, Tom Alrich also argues, that it would be better for vendors to do these analyses themselves and communicate it to all their users/customers, kind of how security advisories already work, but standardized and integrated into automatic tools.
Related Content
Chainguard published a blog post about using purls in SBOMs. It includes a description of the naming problem and an analysis of Grype as container and SBOM scanner. The goal was to conclude how many false positives could be eliminated by including purls in the generated SBOMs. They conclude that around 50-60% could be avoided.
Joseph Hejderup and Henrik Plate compared different tools to generate SBOMs in a case study as part of their presentation In SBOMs We Trust: How Accurate, Complete, and Actionable Are They? at FOSDEM 2023. They analyze three tools, two generic ones and one generating SBOMs at build-time, and take a more in-depth look at the details and accuracy of the generated SBOMs. They anonymize the tools they used, but from the list of tools I found as possible options, I suspect that the two generic solutions are Trivy and Syft.
Another comparison of SBOM generation tools is included in Shubham Girdhar's master thesis Identification of Software Bill of Materials in Container Images. He compares Syft, Tern, Trivy and Dagda, which is not an SBOM tool but a security scanner.
In their article A comparative study of vulnerability reporting by software composition analysis tools (pdf freely available here), Imtiaz, Thorn, and Williams compare vulnerability reporting tools for software supply chain. Instead of SBOM tools they evaluate OWASP Dependency-Check, Snyk, GitHub Dependabot, Maven Security Versions, npm audit, Eclipse Steady and three unnamed commercial tools. Their results are very similar to my findings for SBOM workflows, the number of reported vulnerabilities varies a lot, vulnerabilities can be duplicated, and depend on the identifiers used.
Xia et al. released An Empirical Study on Software Bill of Materials: Where We Stand and the Road Ahead this year. In their study, they do not compare SBOM tools, but instead interview "SBOM practitioners" to assess how SBOMs are used today and how that could be improved. One of their findings is the immaturity of SBOM consumption tools. Although Dependency-Track is mentioned and used a few times, respondents felt, while it was user-friendly, it was not enterprise-ready.
Interlynk maintains an SBOM benchmark. They rank SBOMs by calculating their own quality score for them.
For accurately including CPEs in SBOMs, open source mappings between CPEs and purls exist. Both SCANOSS and nexB maintain a dataset.
Conclusions
Generating SBOMs from containers and automatically, regularly analyzing them for vulnerabilities works, but the results are not as accurate as one would hope. Generating SBOMs during build time rather than from containers images helps, but is not a workflow we can rely on for the secureCodeBox. Some of the problems, like the naming problem, will get better in the future, but the road there is long and the schedule unclear.
For the secureCodeBox, we decided to implement an MVP by using Trivy to generate CycloneDX SBOMs and sending them to Dependency-Track with a persistence hook. Trivy is already used in the secureCodeBox, which makes generating SBOMs and maintenance easier. Syft SBOMs might be better because of their included CPEs, but they mostly matter for the OS packages of a container. If we feel that SBOMs with CPEs are needed, and Trivy has not added that feature, we can still integrate Syft in the future. The secureCodeBox architecture prioritizes configurability and composability, so we are also looking into generating SPDX SBOMs in the future.